

【TensorFlow】优化器AdamOptimizer的源码分析
栏目:公司动态 发布时间:2024-05-13
TensorFlow的优化器基本都继承于"classOptimizer",AdamOptimizer也不例外,本文尝试对该优化器的源码进行解读。源码位置:/tensorflow/python/training/adam.pyAdam从下边的代码块可以看到,AdamOptimizer继承于Optimizer,所以虽然AdamOptimizer类中没
TensorFlow的优化器基本都继承于 "class Optimizer",AdamOptimizer也不例外,本文尝试对该优化器的源码进行解读。源码位置: /tensorflow/python/training/adam.py
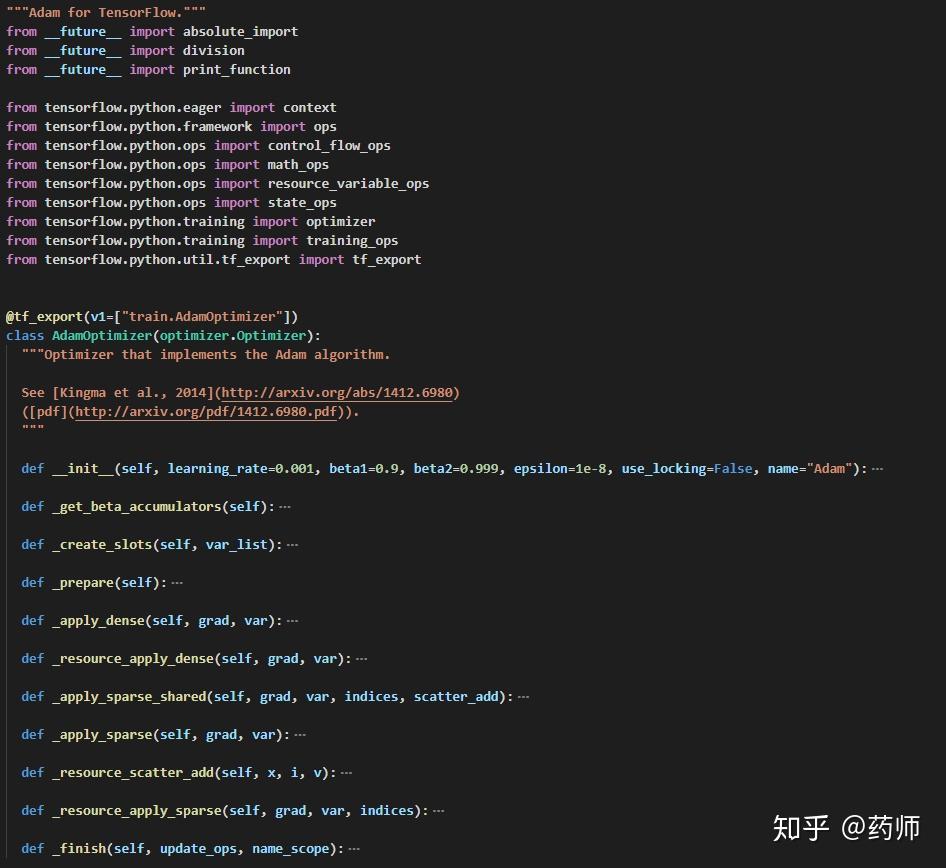
- 从下边的代码块可以看到,
AdamOptimizer继承于Optimizer,所以虽然AdamOptimizer类中没有minimize方法,但父类中有该方法的实现,就可以使用。另外,Adam算法的实现是按照[Kingma et al., 2014]在 ICLR 上发表的论文来实现的。
@tf_export(v1=["train.AdamOptimizer"])
class AdamOptimizer(optimizer.Optimizer):
"""Optimizer that implements the Adam algorithm.
See[Kingma et al., 2014](http://arxiv.org/abs/1412.6980)
([pdf](http://arxiv.org/pdf/1412.6980.pdf)).
"""- 正式介绍代码之前,先来说明一下
Adam算法的计算公式。[Kingma et al., 2014]的论文中给出的方案是每一步的学习率会根据学习率初始值
自适应地改变,而
则可以有效地防止出现分母为零的情况。
Initialize moment and timestep :
Iteration :





_init_函数用于class AdamOptimizer的初始化,学习率默认的是0.001,和
的值默认分别为
0.9和0.999,1e-8。所以在实际使用的时候即使不设置学习率也可以正常使用,因为优化器会自动使用默认值对优化问题求解。
def __init__(self, learning_rate=0.001,
beta1=0.9, beta2=0.999, epsilon=1e-8,
use_locking=False, name="Adam"):
super(AdamOptimizer, self).__init__(use_locking, name)
self._lr = learning_rate
self._beta1 = beta1
self._beta2 = beta2
self._epsilon = epsilon
# Tensor versions of the constructor arguments, created in _prepare().
self._lr_t = None
self._beta1_t = None
self._beta2_t = None
self._epsilon_t = None- 从上边
_init_函数可以看到,除了初始化时传进去的参数,优化器自身还存储了这些参数的 Tensor 版本,而这个转换是在_prepare函数中通过convert_to_tensor方法来实现的。 这个函数在/tensorflow/python/framework/ops.py#L1021处。,功能就是Converts the given 'value' to a 'Tensor',它允许被接受的值有'Tensor' objects, numpy arrays, Python lists, and Python scalars。
def _prepare(self):
lr = self._call_if_callable(self._lr)
beta1 = self._call_if_callable(self._beta1)
beta2 = self._call_if_callable(self._beta2)
epsilon = self._call_if_callable(self._epsilon)
self._lr_t = ops.convert_to_tensor(lr, name="learning_rate")
self._beta1_t = ops.convert_to_tensor(beta1, name="beta1")
self._beta2_t = ops.convert_to_tensor(beta2, name="beta2")
self._epsilon_t = ops.convert_to_tensor(epsilon, name="epsilon")_get_beta_accumulators函数和_create_slots函数可以放在一起看。顾名思义,_create_slots函数就是用来创建参数的,从代码中可以看到被创建的参数有、
、
次方(
beta1_power)和beta2_power)。_get_beta_accumulators函数则是用来获取
def _get_beta_accumulators(self):
with ops.init_scope():
if context.executing_eagerly():
graph = None
else:
graph = ops.get_default_graph()
return (self._get_non_slot_variable("beta1_power", graph=graph),
self._get_non_slot_variable("beta2_power", graph=graph))
def _create_slots(self, var_list):
first_var = min(var_list, key=lambda x: x.name)
self._create_non_slot_variable(initial_value=self._beta1,
name="beta1_power",
colocate_with=first_var)
self._create_non_slot_variable(initial_value=self._beta2,
name="beta2_power",
colocate_with=first_var)
# Create slots for the first and second moments.
for v in var_list:
self._zeros_slot(v, "m", self._name)
self._zeros_slot(v, "v", self._name)_apply_dense、_resource_apply_dense、_apply_sparse、_resource_apply_sparse均是对父类中方法的重写。- 函数
_apply_dense和_resource_apply_dense的实现中分别使用了training_ops.apply_adam和training_ops.resource_apply_adam方法,所以Adam算法迭代操作的具体实现并不在此处,通过仔细分析代码发现是在/tensorflow/core/kernels/training_ops.h处定义并在/tensorflow/core/kernels/training_ops.cc处实现。
def _apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.apply_adam(
var,
m,
v,
math_ops.cast(beta1_power, var.dtype.base_dtype),
math_ops.cast(beta2_power, var.dtype.base_dtype),
math_ops.cast(self._lr_t, var.dtype.base_dtype),
math_ops.cast(self._beta1_t, var.dtype.base_dtype),
math_ops.cast(self._beta2_t, var.dtype.base_dtype),
math_ops.cast(self._epsilon_t, var.dtype.base_dtype),
grad,
use_locking=self._use_locking).op
def _resource_apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.resource_apply_adam(
var.handle,
m.handle,
v.handle,
math_ops.cast(beta1_power, grad.dtype.base_dtype),
math_ops.cast(beta2_power, grad.dtype.base_dtype),
math_ops.cast(self._lr_t, grad.dtype.base_dtype),
math_ops.cast(self._beta1_t, grad.dtype.base_dtype),
math_ops.cast(self._beta2_t, grad.dtype.base_dtype),
math_ops.cast(self._epsilon_t, grad.dtype.base_dtype),
grad,
use_locking=self._use_locking)// train_ops.h : 138 Line
template <typename Device, typename T>
struct ApplyAdam {
void operator()(const Device& d, typename TTypes<T>::Flat var,
typename TTypes<T>::Flat m, typename TTypes<T>::Flat v,
typename TTypes<T>::ConstScalar beta1_power,
typename TTypes<T>::ConstScalar beta2_power,
typename TTypes<T>::ConstScalar lr,
typename TTypes<T>::ConstScalar beta1,
typename TTypes<T>::ConstScalar beta2,
typename TTypes<T>::ConstScalar epsilon,
typename TTypes<T>::ConstFlat grad, bool use_nesterov);
};
// train_ops.cc : 303 Line
template <typename Device, typename T>
struct ApplyAdamNonCuda {
void operator()(const Device& d, typename TTypes<T>::Flat var,
typename TTypes<T>::Flat m, typename TTypes<T>::Flat v,
typename TTypes<T>::ConstScalar beta1_power,
typename TTypes<T>::ConstScalar beta2_power,
typename TTypes<T>::ConstScalar lr,
typename TTypes<T>::ConstScalar beta1,
typename TTypes<T>::ConstScalar beta2,
typename TTypes<T>::ConstScalar epsilon,
typename TTypes<T>::ConstFlat grad, bool use_nesterov)
// ...
const T alpha = lr() * Eigen::numext::sqrt(T(1) - beta2_power()) / (T(1) - beta1_power());
// ...
if (use_nesterov) {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= ((g * (T(1) - beta1()) + beta1() * m) * alpha) / (v.sqrt() + epsilon());
} else {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= (m * alpha) / (v.sqrt() + epsilon());
}
// ...
// train_ops.cc : 392 Line
template <typename T>
struct ApplyAdam<CPUDevice, T> : ApplyAdamNonCuda<CPUDevice, T> {};
- 在
http://train_ops.cc中,
- 函数
_apply_sparse和_resource_apply_sparse主要用在稀疏向量的更新操作上,而具体的实现是在函数_apply_sparse_shared中。
def _apply_sparse(self, grad, var):
return self._apply_sparse_shared(grad.values, var, grad.indices,
lambda x, i, v: state_ops.scatter_add(x, i, v, use_locking=self._use_locking))
def _resource_apply_sparse(self, grad, var, indices):
return self._apply_sparse_shared(grad, var, indices, self._resource_scatter_add)
def _resource_scatter_add(self, x, i, v):
with ops.control_dependencies([resource_variable_ops.resource_scatter_add(x.handle, i, v)]):
return x.value()- 在介绍函数
_apply_sparse_shared之前,先来介绍下需要用到的state_ops.scatter_add函数。该函数定义在/tensorflow/python/ops/state_ops.py#L372处,作用是Adds sparse updates to the variable referenced by 'resource',即完成稀疏 Tensor 的加操作,如下图所示。
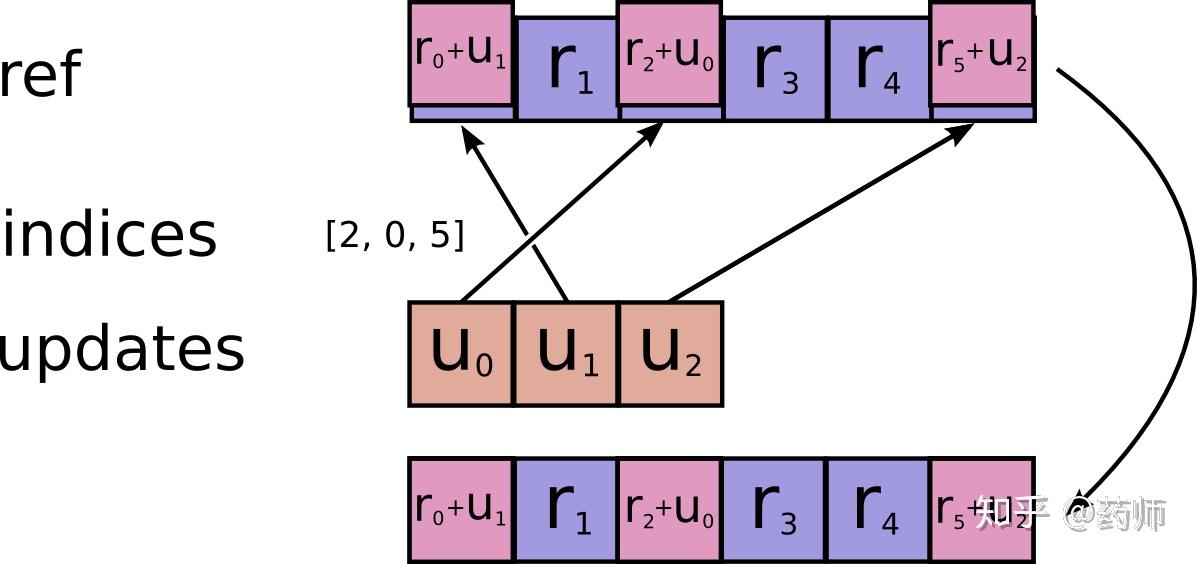
- 现在回过头来说一下函数
_apply_sparse_shared。代码很简单,首先是获取所需要的参数值并将其存储在变量里,接着就是按照 Adam 算法的流程,首先计算学习率lr=...),接着计算两个 Momentum ,由于是稀疏 Tensor 的更新,所以在算出更新值之后要使用scatter_add来完成加法操作。注意这个scatter_add是作为函数参数传进来的,这样做的好处是当需要别的特定加法操作时可随时进行修改。 最后将var_update和m_t、v_t的更新操作放进control_flow_ops.group中。
def _apply_sparse_shared(self, grad, var, indices, scatter_add):
beta1_power, beta2_power = self._get_beta_accumulators()
beta1_power = math_ops.cast(beta1_power, var.dtype.base_dtype)
beta2_power = math_ops.cast(beta2_power, var.dtype.base_dtype)
lr_t = math_ops.cast(self._lr_t, var.dtype.base_dtype)
beta1_t = math_ops.cast(self._beta1_t, var.dtype.base_dtype)
beta2_t = math_ops.cast(self._beta2_t, var.dtype.base_dtype)
epsilon_t = math_ops.cast(self._epsilon_t, var.dtype.base_dtype)
lr = (lr_t * math_ops.sqrt(1 - beta2_power) / (1 - beta1_power))
# m_t=beta1 * m + (1 - beta1) * g_t
m = self.get_slot(var, "m")
m_scaled_g_values = grad * (1 - beta1_t)
m_t = state_ops.assign(m, m * beta1_t, use_locking=self._use_locking)
with ops.control_dependencies([m_t]):
m_t = scatter_add(m, indices, m_scaled_g_values)
# v_t=beta2 * v + (1 - beta2) * (g_t * g_t)
v = self.get_slot(var, "v")
v_scaled_g_values = (grad * grad) * (1 - beta2_t)
v_t = state_ops.assign(v, v * beta2_t, use_locking=self._use_locking)
with ops.control_dependencies([v_t]):
v_t = scatter_add(v, indices, v_scaled_g_values)
v_sqrt = math_ops.sqrt(v_t)
var_update = state_ops.assign_sub(var, lr * m_t / (v_sqrt + epsilon_t), use_locking=self._use_locking)
return control_flow_ops.group(*[var_update, m_t, v_t])- 现在来说一下最后一个函数
_finish。前边介绍了那么多,但是一直没有提到beta1_power)和beta2_power)是如何计算的,其实 TensorFlow 把这两个参数的更新放到了一个单独的函数中去,就是这个_finish函数。代码中是通过之前存储的和
来计算的。最后将这两个更新操作放进
control_flow_ops.group中。
def _finish(self, update_ops, name_scope):
# Update the power accumulators.
with ops.control_dependencies(update_ops):
beta1_power, beta2_power = self._get_beta_accumulators()
with ops.colocate_with(beta1_power):
update_beta1 = beta1_power.assign(beta1_power * self._beta1_t, use_locking=self._use_locking)
update_beta2 = beta2_power.assign(beta2_power * self._beta2_t, use_locking=self._use_locking)
return control_flow_ops.group(*update_ops + [update_beta1, update_beta2], name=name_scope)- 我们发现 Adam 算法的更新计算操作都会放进
control_flow_ops.group中,group这个函数的具体实现是在/tensorflow/python/ops/control_flow_ops.py#L3595处。
# TODO(touts): Accept "inputs" as a list.
@tf_export("group")
def group(*inputs, **kwargs):
"""Create an op that groups multiple operations.
When this op finishes, all ops in `inputs` have finished. This op has no output.
See also `tf.tuple` and `tf.control_dependencies`.
Args:
*inputs: Zero or more tensors to group.
name: A name for this operation (optional).
Returns:
An Operation that executes all its inputs.
Raises:
ValueError: If an unknown keyword argument is provided.
"""
